
 zyc
1189738e28
改变参数
zyc
1189738e28
改变参数
|
5 anos atrás | |
|---|---|---|
| .. | ||
| PPOCRLabel | 5 anos atrás | |
| StyleText | 5 anos atrás | |
| configs | 5 anos atrás | |
| deploy | 5 anos atrás | |
| doc | 5 anos atrás | |
| ppocr | 5 anos atrás | |
| tools | 5 anos atrás | |
| .gitignore | 5 anos atrás | |
| .pre-commit-config.yaml | 5 anos atrás | |
| .style.yapf | 5 anos atrás | |
| LICENSE | 5 anos atrás | |
| MANIFEST.in | 5 anos atrás | |
| README.md | 5 anos atrás | |
| README_ch.md | 5 anos atrás | |
| __init__.py | 5 anos atrás | |
| paddleocr.py | 5 anos atrás | |
| requirements.txt | 5 anos atrás | |
| setup.py | 5 anos atrás | |
| train.sh | 5 anos atrás | |
README.md
English | 简体中文
Introduction
PaddleOCR aims to create multilingual, awesome, leading, and practical OCR tools that help users train better models and apply them into practice.
Notice
PaddleOCR supports both dynamic graph and static graph programming paradigm
- Dynamic graph: dygraph branch (default), supported by paddle 2.0.0 (installation)
- Static graph: develop branch
Recent updates
- 2021.2.8 Release PaddleOCRv2.0(branch release/2.0) and set as default branch. Check release note here: https://github.com/PaddlePaddle/PaddleOCR/releases/tag/v2.0.0
- 2021.1.21 update more than 25+ multilingual recognition models models list, including:English, Chinese, German, French, Japanese,Spanish,Portuguese Russia Arabic and so on. Models for more languages will continue to be updated Develop Plan.
- 2020.12.15 update Data synthesis tool, i.e., Style-Text,easy to synthesize a large number of images which are similar to the target scene image.
- 2020.11.25 Update a new data annotation tool, i.e., PPOCRLabel, which is helpful to improve the labeling efficiency. Moreover, the labeling results can be used in training of the PP-OCR system directly.
- 2020.9.22 Update the PP-OCR technical article, https://arxiv.org/abs/2009.09941
- more
Features
- PPOCR series of high-quality pre-trained models, comparable to commercial effects
- Ultra lightweight ppocr_mobile series models: detection (3.0M) + direction classifier (1.4M) + recognition (5.0M) = 9.4M
- General ppocr_server series models: detection (47.1M) + direction classifier (1.4M) + recognition (94.9M) = 143.4M
- Support Chinese, English, and digit recognition, vertical text recognition, and long text recognition
- Support multi-language recognition: Korean, Japanese, German, French
- Rich toolkits related to the OCR areas
- Semi-automatic data annotation tool, i.e., PPOCRLabel: support fast and efficient data annotation
- Data synthesis tool, i.e., Style-Text: easy to synthesize a large number of images which are similar to the target scene image
- Support user-defined training, provides rich predictive inference deployment solutions
- Support PIP installation, easy to use
- Support Linux, Windows, MacOS and other systems
Visualization

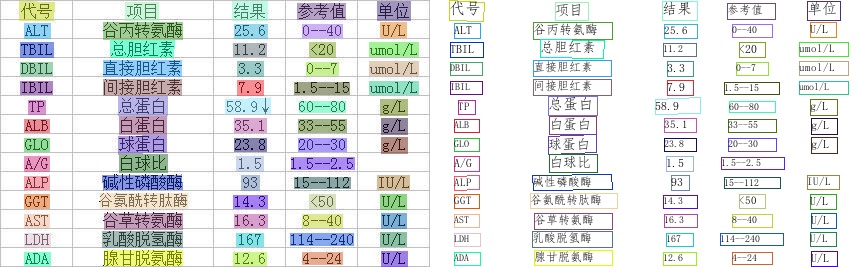
The above pictures are the visualizations of the general ppocr_server model. For more effect pictures, please see More visualizations.
Community
- Scan the QR code below with your Wechat, you can access to official technical exchange group. Look forward to your participation.

Quick Experience
You can also quickly experience the ultra-lightweight OCR : Online Experience
Mobile DEMO experience (based on EasyEdge and Paddle-Lite, supports iOS and Android systems): Sign in to the website to obtain the QR code for installing the App
Also, you can scan the QR code below to install the App (Android support only)

PP-OCR 2.0 series model list(Update on Dec 15)
Note : Compared with models 1.1, which are trained with static graph programming paradigm, models 2.0 are the dynamic graph trained version and achieve close performance.
| Model introduction | Model name | Recommended scene | Detection model | Direction classifier | Recognition model |
|---|---|---|---|---|---|
| Chinese and English ultra-lightweight OCR model (9.4M) | ch_ppocr_mobile_v2.0_xx | Mobile & server | inference model / pre-trained model | inference model / pre-trained model | inference model / pre-trained model |
| Chinese and English general OCR model (143.4M) | ch_ppocr_server_v2.0_xx | Server | inference model / pre-trained model | inference model / pre-trained model | inference model / pre-trained model |
For more model downloads (including multiple languages), please refer to PP-OCR v2.0 series model downloads.
For a new language request, please refer to Guideline for new language_requests.
Tutorials
- Installation
- Quick Start
- Code Structure
- Algorithm Introduction
- Model Training/Evaluation
- Inference and Deployment
- Data Annotation and Synthesis
- Datasets
- Visualization
- New language requests
- FAQ
- Community
- References
- License
- Contribution
PP-OCR Pipeline
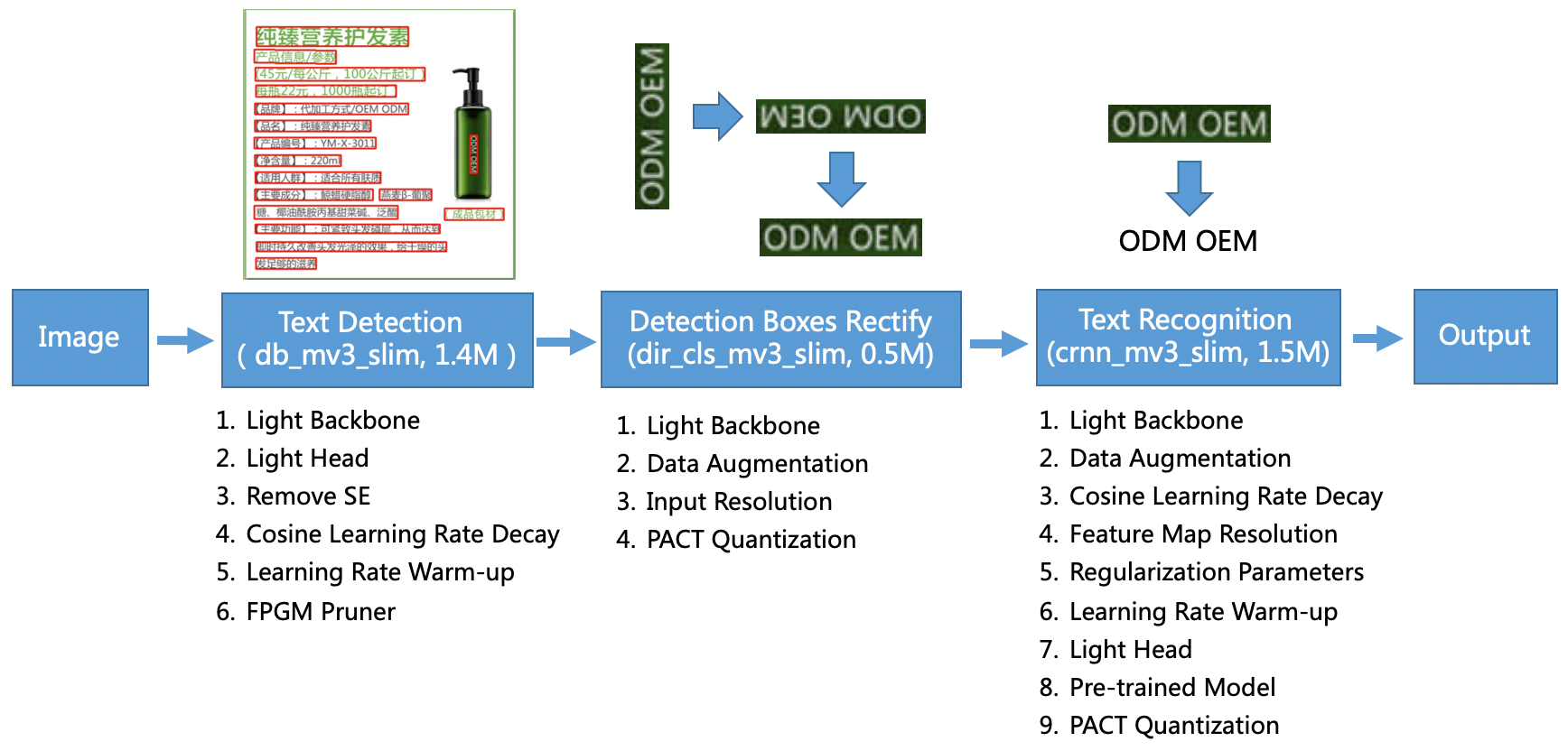
PP-OCR is a practical ultra-lightweight OCR system. It is mainly composed of three parts: DB text detection[2], detection frame correction and CRNN text recognition[7]. The system adopts 19 effective strategies from 8 aspects including backbone network selection and adjustment, prediction head design, data augmentation, learning rate transformation strategy, regularization parameter selection, pre-training model use, and automatic model tailoring and quantization to optimize and slim down the models of each module. The final results are an ultra-lightweight Chinese and English OCR model with an overall size of 3.5M and a 2.8M English digital OCR model. For more details, please refer to the PP-OCR technical article (https://arxiv.org/abs/2009.09941). Besides, The implementation of the FPGM Pruner [8] and PACT quantization [9] is based on PaddleSlim.
Visualization more
Chinese OCR model




English OCR model

Multilingual OCR model


Guideline for new language requests
If you want to request a new language support, a PR with 2 following files are needed:
In folder ppocr/utils/dict, it is necessary to submit the dict text to this path and name it with
{language}_dict.txtthat contains a list of all characters. Please see the format example from other files in that folder.In folder ppocr/utils/corpus, it is necessary to submit the corpus to this path and name it with
{language}_corpus.txtthat contains a list of words in your language. Maybe, 50000 words per language is necessary at least. Of course, the more, the better.
If your language has unique elements, please tell me in advance within any way, such as useful links, wikipedia and so on.
More details, please refer to Multilingual OCR Development Plan.
License
This project is released under Apache 2.0 license
Contribution
We welcome all the contributions to PaddleOCR and appreciate for your feedback very much.
- Many thanks to Khanh Tran and Karl Horky for contributing and revising the English documentation.
- Many thanks to zhangxin for contributing the new visualize function、add .gitignore and discard set PYTHONPATH manually.
- Many thanks to lyl120117 for contributing the code for printing the network structure.
- Thanks xiangyubo for contributing the handwritten Chinese OCR datasets.
- Thanks authorfu for contributing Android demo and xiadeye contributing iOS demo, respectively.
- Thanks BeyondYourself for contributing many great suggestions and simplifying part of the code style.
- Thanks tangmq for contributing Dockerized deployment services to PaddleOCR and supporting the rapid release of callable Restful API services.
- Thanks lijinhan for contributing a new way, i.e., java SpringBoot, to achieve the request for the Hubserving deployment.
- Thanks Mejans for contributing the Occitan corpus and character set.
- Thanks LKKlein for contributing a new deploying package with the Golang program language.
- Thanks Evezerest, ninetailskim, edencfc, BeyondYourself and 1084667371 for contributing a new data annotation tool, i.e., PPOCRLabel。