
README_ch.md 11 KB
English | 简体中文
简介
PaddleOCR旨在打造一套丰富、领先、且实用的OCR工具库,助力使用者训练出更好的模型,并应用落地。
注意
PaddleOCR同时支持动态图与静态图两种编程范式
- 动态图版本:dygraph分支(默认),需将paddle版本升级至2.0.0(快速安装)
- 静态图版本:develop分支
近期更新
- 2021.3.8 FAQ新增6个高频问题,总数183个,每周一都会更新,欢迎大家持续关注。
- 2021.2.8 正式发布PaddleOCRv2.0(branch release/2.0)并设置为推荐用户使用的默认分支. 发布的详细内容,请参考: https://github.com/PaddlePaddle/PaddleOCR/releases/tag/v2.0.0
- 2021.1.26,28,29 PaddleOCR官方研发团队带来技术深入解读三日直播课,1月26日、28日、29日晚上19:30,直播地址
- 2021.1.21 更新多语言识别模型,目前支持语种超过27种,多语言模型下载,包括中文简体、中文繁体、英文、法文、德文、韩文、日文、意大利文、西班牙文、葡萄牙文、俄罗斯文、阿拉伯文等,后续计划可以参考多语言研发计划
- 2020.12.15 更新数据合成工具Style-Text,可以批量合成大量与目标场景类似的图像,在多个场景验证,效果明显提升。
- 2020.11.25 更新半自动标注工具PPOCRLabel,辅助开发者高效完成标注任务,输出格式与PP-OCR训练任务完美衔接。
- 2020.9.22 更新PP-OCR技术文章,https://arxiv.org/abs/2009.09941
- More
特性
- PPOCR系列高质量预训练模型,准确的识别效果
- 超轻量ppocr_mobile移动端系列:检测(3.0M)+方向分类器(1.4M)+ 识别(5.0M)= 9.4M
- 通用ppocr_server系列:检测(47.1M)+方向分类器(1.4M)+ 识别(94.9M)= 143.4M
- 支持中英文数字组合识别、竖排文本识别、长文本识别
- 支持多语言识别:韩语、日语、德语、法语
- 丰富易用的OCR相关工具组件
- 半自动数据标注工具PPOCRLabel:支持快速高效的数据标注
- 数据合成工具Style-Text:批量合成大量与目标场景类似的图像
- 支持用户自定义训练,提供丰富的预测推理部署方案
- 支持PIP快速安装使用
- 可运行于Linux、Windows、MacOS等多种系统
效果展示

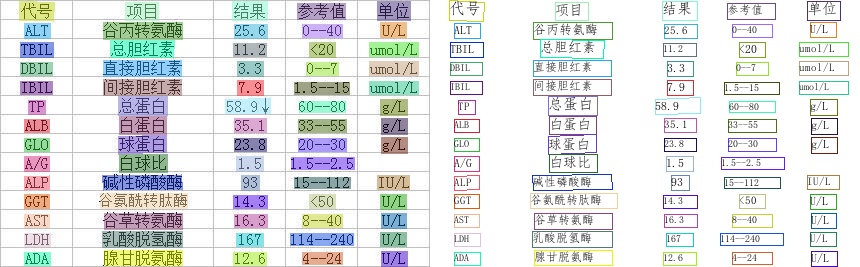
上图是通用ppocr_server模型效果展示,更多效果图请见效果展示页面。
欢迎加入PaddleOCR技术交流群
- 微信扫描二维码加入官方交流群,获得更高效的问题答疑,与各行各业开发者充分交流,期待您的加入。

快速体验
PC端:超轻量级中文OCR在线体验地址:https://www.paddlepaddle.org.cn/hub/scene/ocr
移动端:安装包DEMO下载地址(基于EasyEdge和Paddle-Lite, 支持iOS和Android系统),Android手机也可以直接扫描下面二维码安装体验。

- 代码体验:从快速安装 开始
PP-OCR 2.0系列模型列表(更新中)
说明 :2.0版模型和1.1版模型的主要区别在于动态图训练vs.静态图训练,模型性能上无明显差距。 | 模型简介 | 模型名称 |推荐场景 | 检测模型 | 方向分类器 | 识别模型 | | ------------ | --------------- | ----------------|---- | ---------- | -------- | | 中英文超轻量OCR模型(9.4M) | ch_ppocr_mobile_v2.0_xx |移动端&服务器端|推理模型 / 预训练模型|推理模型 / 预训练模型 |推理模型 / 预训练模型 | | 中英文通用OCR模型(143.4M) |ch_ppocr_server_v2.0_xx|服务器端 |推理模型 / 预训练模型 |推理模型 / 预训练模型 |推理模型 / 预训练模型 |
更多模型下载(包括多语言),可以参考PP-OCR v2.0 系列模型下载
文档教程
PP-OCR Pipline
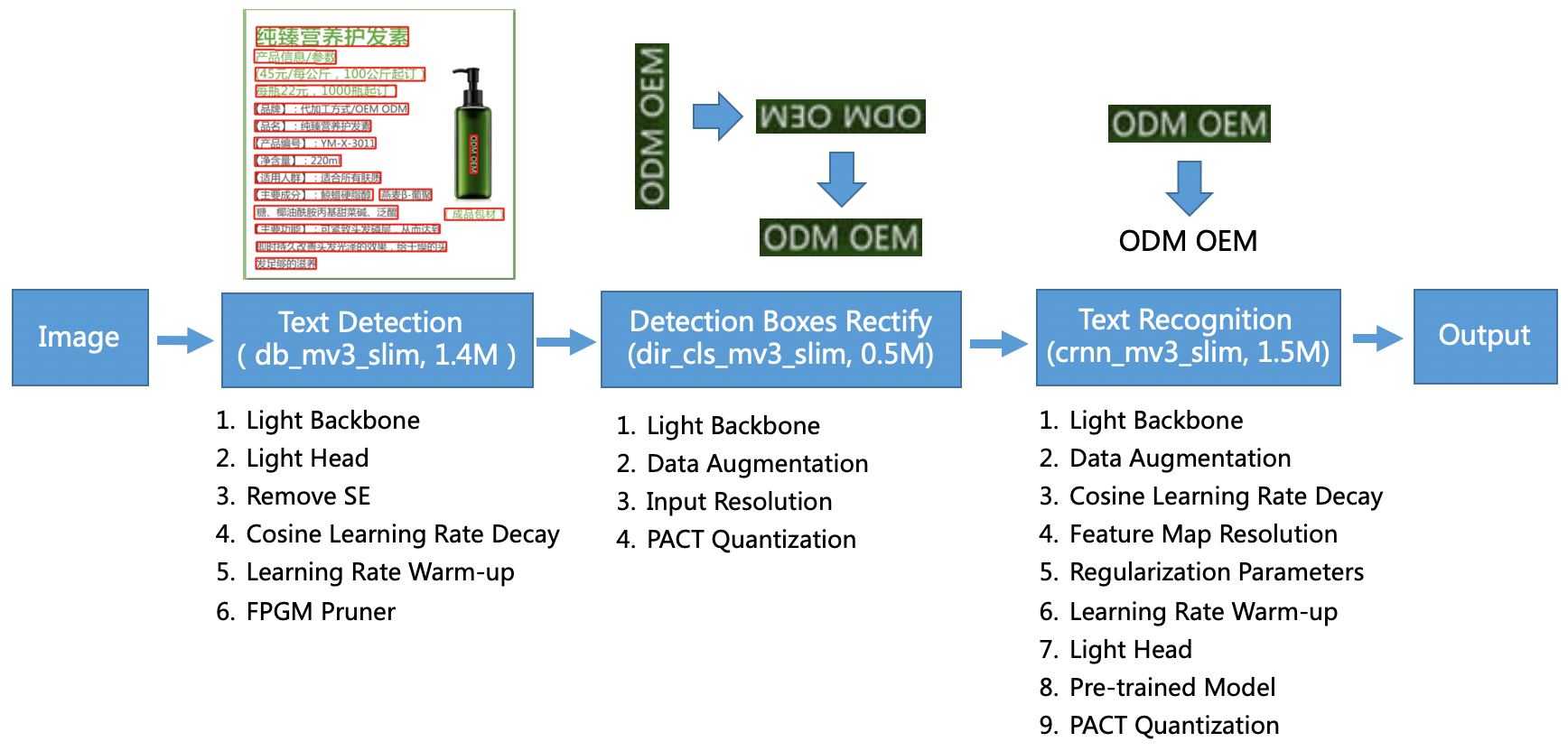
PP-OCR是一个实用的超轻量OCR系统。主要由DB文本检测[2]、检测框矫正和CRNN文本识别三部分组成[7]。该系统从骨干网络选择和调整、预测头部的设计、数据增强、学习率变换策略、正则化参数选择、预训练模型使用以及模型自动裁剪量化8个方面,采用19个有效策略,对各个模块的模型进行效果调优和瘦身,最终得到整体大小为3.5M的超轻量中英文OCR和2.8M的英文数字OCR。更多细节请参考PP-OCR技术方案 https://arxiv.org/abs/2009.09941 。其中FPGM裁剪器[8]和PACT量化[9]的实现可以参考PaddleSlim。
效果展示 more
中文模型




英文模型

其他语言模型


许可证书
本项目的发布受Apache 2.0 license许可认证。
贡献代码
我们非常欢迎你为PaddleOCR贡献代码,也十分感谢你的反馈。
- 非常感谢 Khanh Tran 和 Karl Horky 贡献修改英文文档
- 非常感谢 zhangxin(Blog) 贡献新的可视化方式、添加.gitignore、处理手动设置PYTHONPATH环境变量的问题
- 非常感谢 lyl120117 贡献打印网络结构的代码
- 非常感谢 xiangyubo 贡献手写中文OCR数据集
- 非常感谢 authorfu 贡献Android和xiadeye 贡献IOS的demo代码
- 非常感谢 BeyondYourself 给PaddleOCR提了很多非常棒的建议,并简化了PaddleOCR的部分代码风格。
- 非常感谢 tangmq 给PaddleOCR增加Docker化部署服务,支持快速发布可调用的Restful API服务。
- 非常感谢 lijinhan 给PaddleOCR增加java SpringBoot 调用OCR Hubserving接口完成对OCR服务化部署的使用。
- 非常感谢 Mejans 给PaddleOCR增加新语言奥克西坦语Occitan的字典和语料。
- 非常感谢 Evezerest, ninetailskim, edencfc, BeyondYourself, 1084667371 贡献了PPOCRLabel的完整代码。